Learn AWS by doing.
An OpenEnv-compatible RL environment where agents execute real AWS CLI commands against a vendored MiniStack simulator that responds with production-equivalent JSON. 120+ tasks across 5 tiers (warmup → expert) with adaptive selection, mastery tracking, spaced repetition, chaos injection and drift-detection scenarios — every feature designed to keep the reward signal honest and prevent the agent from gaming it. Trained end-to-end with a 1,500-row synthetic SFT dataset and TRL GRPO with 8-way parallel rollouts on a single GPU.
List resources — single read-only commands
- Run one AWS CLI command to list or describe a resource type
- S3 buckets, EC2 instances, DynamoDB tables, Lambda functions, RDS, EBS volumes
- Graded by command_match — checks operation + service pair
- No setup required, no state mutations
Create single resources with verification
- Create an S3 bucket, DynamoDB table, SQS queue, or Lambda function
- Graded by resource_creation — verifies the exact resource exists in AWS Infrastructure Simulator
- Introduces resource name validation — "my-bucket-2" won't satisfy a check for "my-bucket"
- First tier where idempotency bonus (+0.02) can be earned
Multi-step workflows — create, configure, connect
- Ordered sequences: create a bucket then enable versioning, create a table then add an item
- Graded by multi_step — validates each step was completed in order
- Chaos injection begins at 10% probability — resources may be silently mutated mid-episode
- Rollback penalty (-0.1) starts to matter with multi-step create/delete patterns
Cross-service architectures spanning multiple AWS services
- Wire Lambda to SQS, configure API Gateway with integrations, build event-driven pipelines
- Graded by multi_step + services — all required services must be configured
- Chaos injection escalates to 20% probability — DynamoDB throughput, Lambda configs may change
- Hints cost more: 3 hints = only 61% of max reward (0.85³ decay)
SRE incidents & drift detection — diagnose and fix
- Fix overly permissive S3 policies, replace broad IAM inline policies, repair broken infra
- Graded by state_checks — actual CLI commands run against MiniStack at grading time
- Chaos injection at 30% probability — maximum perturbation frequency
- 9 drift detection tasks — correct infra is provisioned, then 2–3 random mutations applied from a pool
- Agent must audit environment, discover which resources drifted, and fix only those
- Drift is randomized per episode — prevents memorization of fix sequences
Curriculum & Training
Adaptive learning system that tracks mastery and selects optimal tasks.
Reward Shaping
Dense reward signals that encourage operational discipline and real progress.
Resilience & Adaptability
Features that test agent robustness under unpredictable conditions.
Security Posture Audit
Tests reasoning about configuration state — working but insecure infrastructure the agent must analyze and harden.
Anti-Reward-Hacking
8 defense layers that prevent the agent from gaming the reward system.
aws CLI commands allowed
SFT → GRPO Training Pipeline
Two-stage training on unsloth/Qwen2.5-Coder-3B-Instruct-bnb-4bit — the
base picked from an 11-model benchmark on 27 held-out prompts. Stage 1: LoRA SFT on 1,500 synthetic
trajectories spanning 5 shapes. Stage 2: TRL GRPO with multi-turn rollouts, group-relative advantages, KL
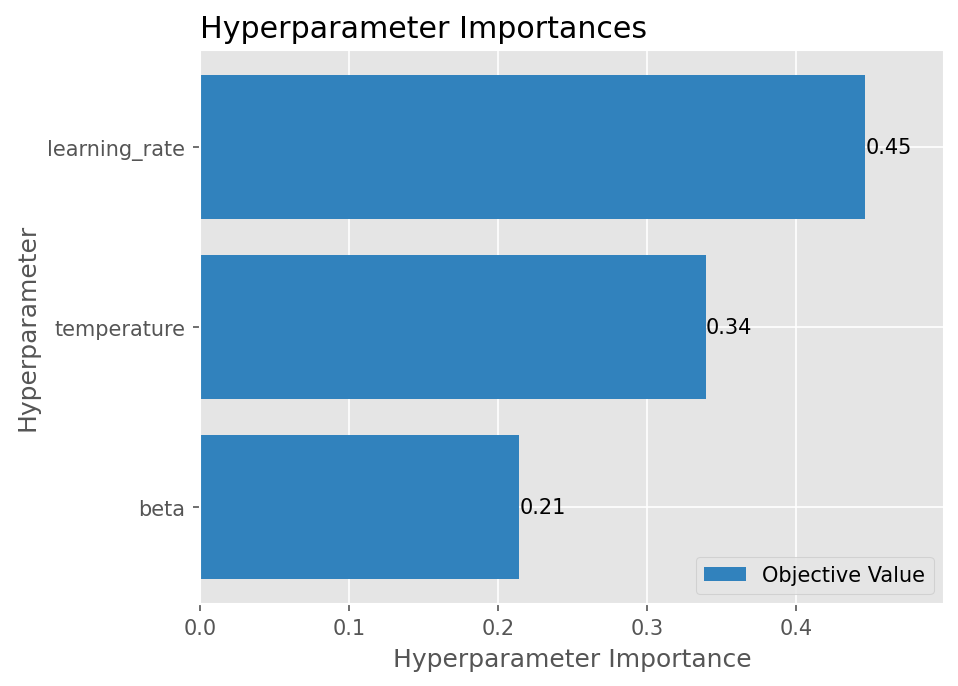
to SFT reference, and Optuna search over an 8-dim hyperparameter space.
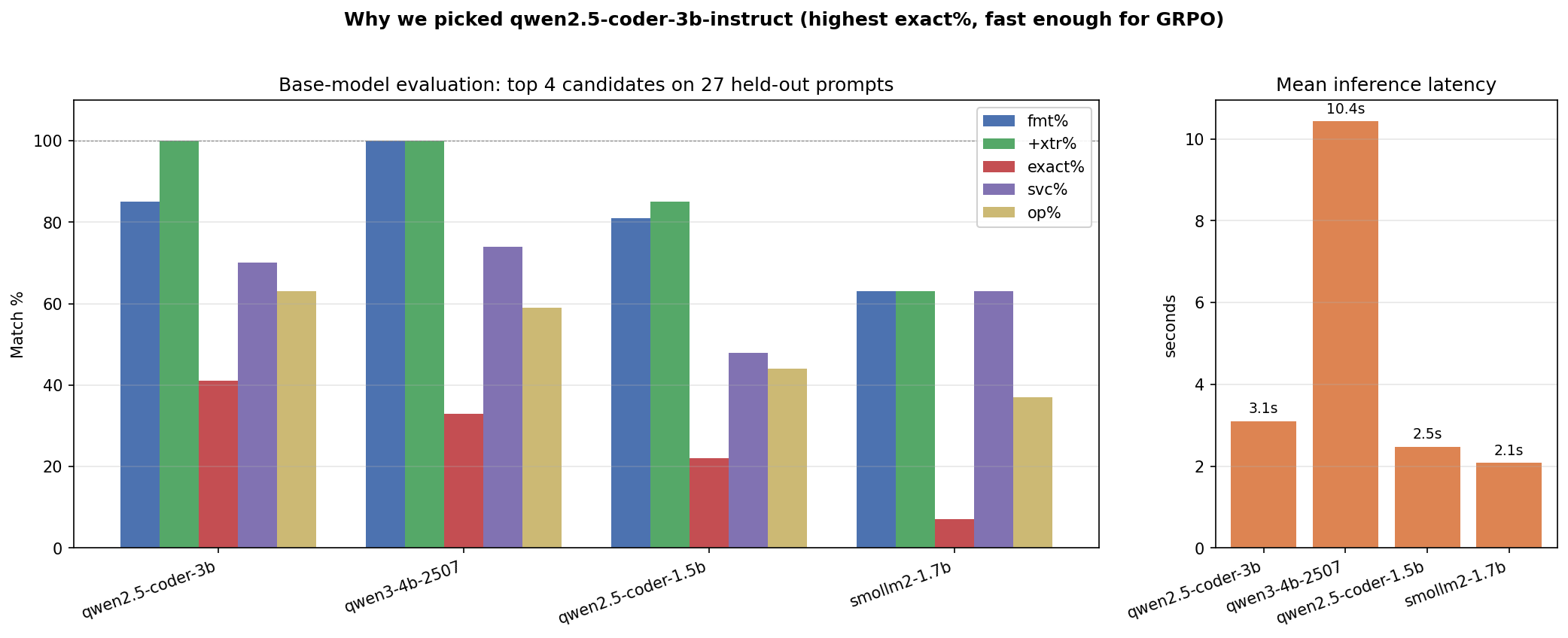
Base-Model Selection
11 chat models × 27 held-out prompts. Qwen2.5-Coder-3B-Instruct wins on every metric that matters: 41% exact match, 63% operation match, 3.1 s/call (3× faster than the 4B runner-up).
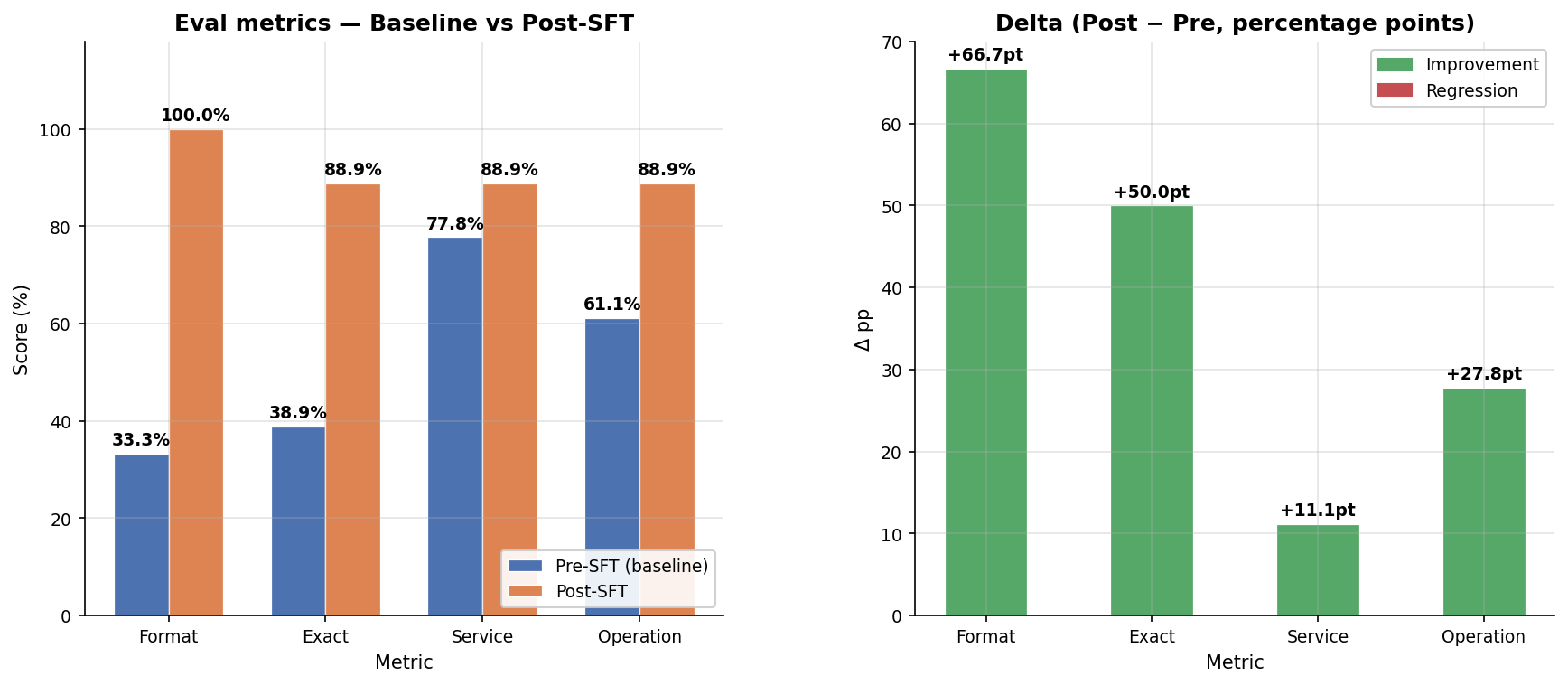
Base vs SFT — Eval Delta
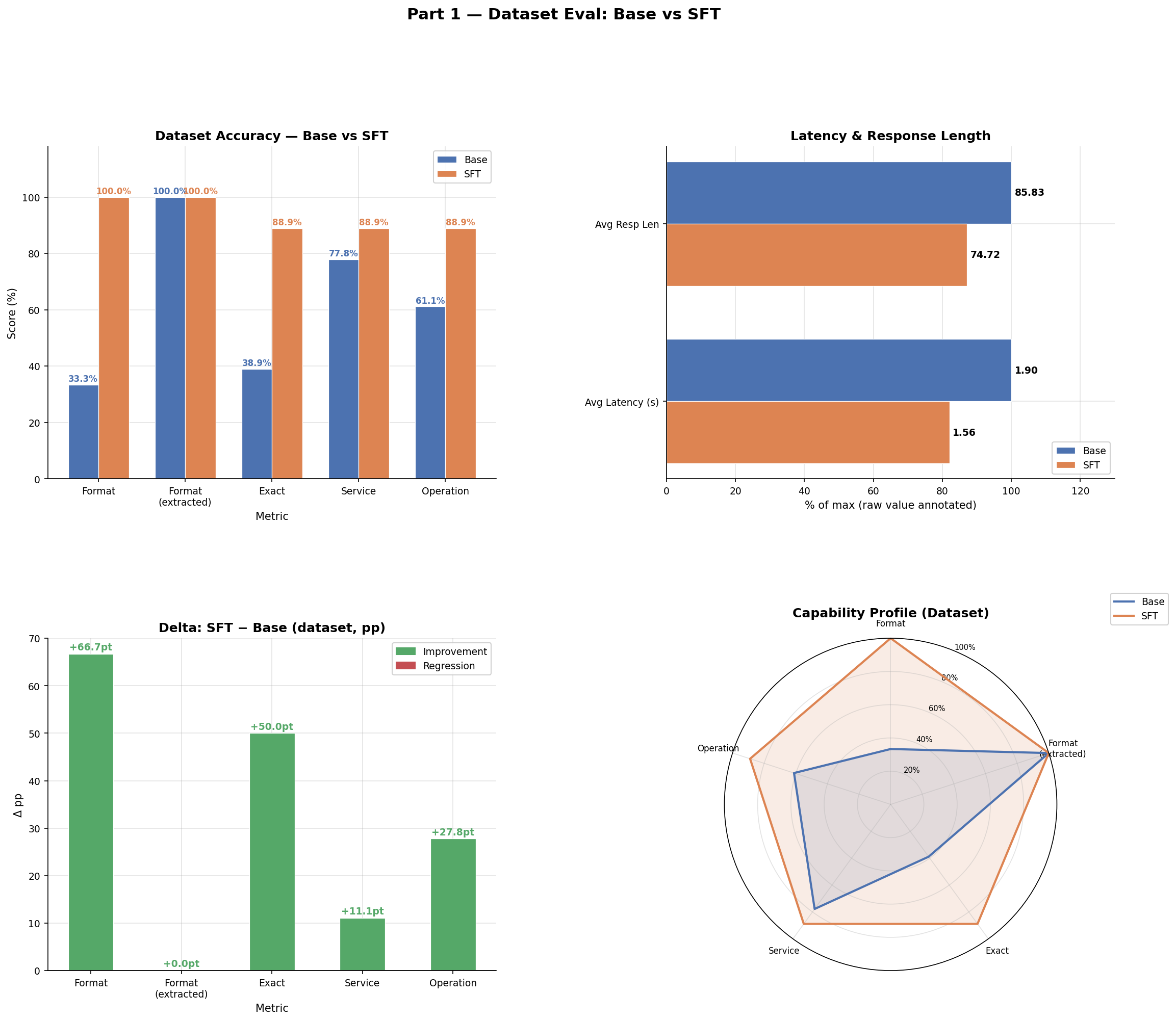
After running the SFT pipeline end-to-end, format compliance is now perfect and exact-match jumped from 39% to 89%.
| Metric | Base | Post-SFT | Δ |
|---|---|---|---|
| Format | 33.3% | 100.0% | +66.7 pp |
| Exact match | 38.9% | 88.9% | +50.0 pp |
| Service match | 77.8% | 88.9% | +11.1 pp |
| Operation match | 61.1% | 88.9% | +27.8 pp |
| Latency | 2.03 s | 1.40 s | −0.63 s |
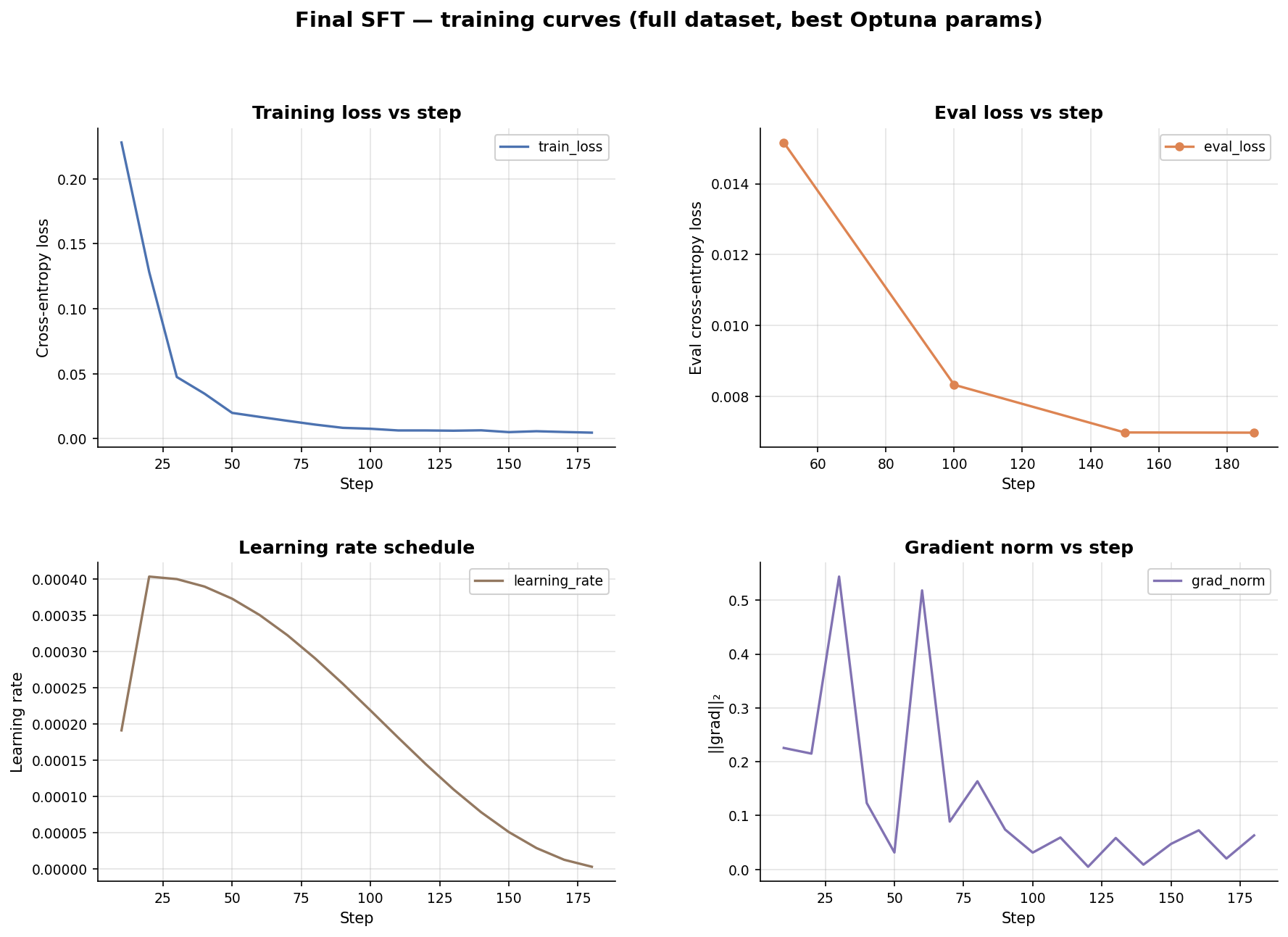
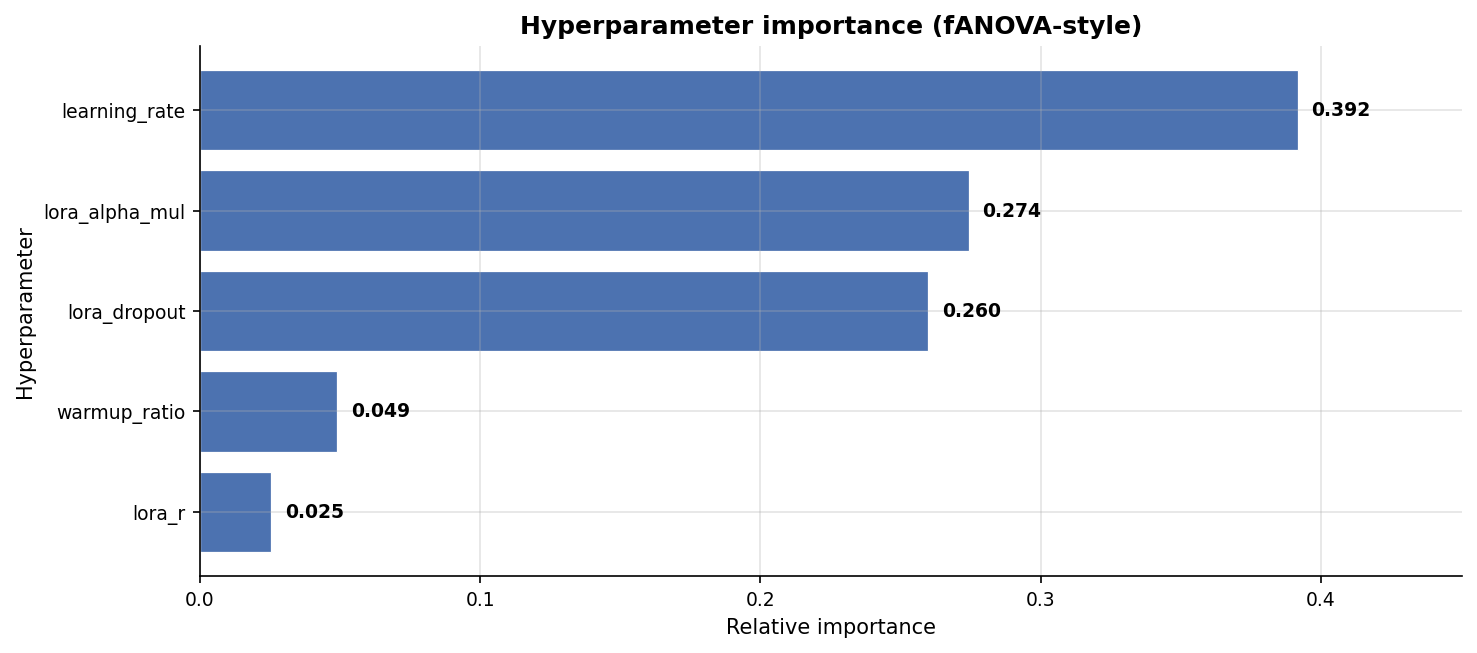
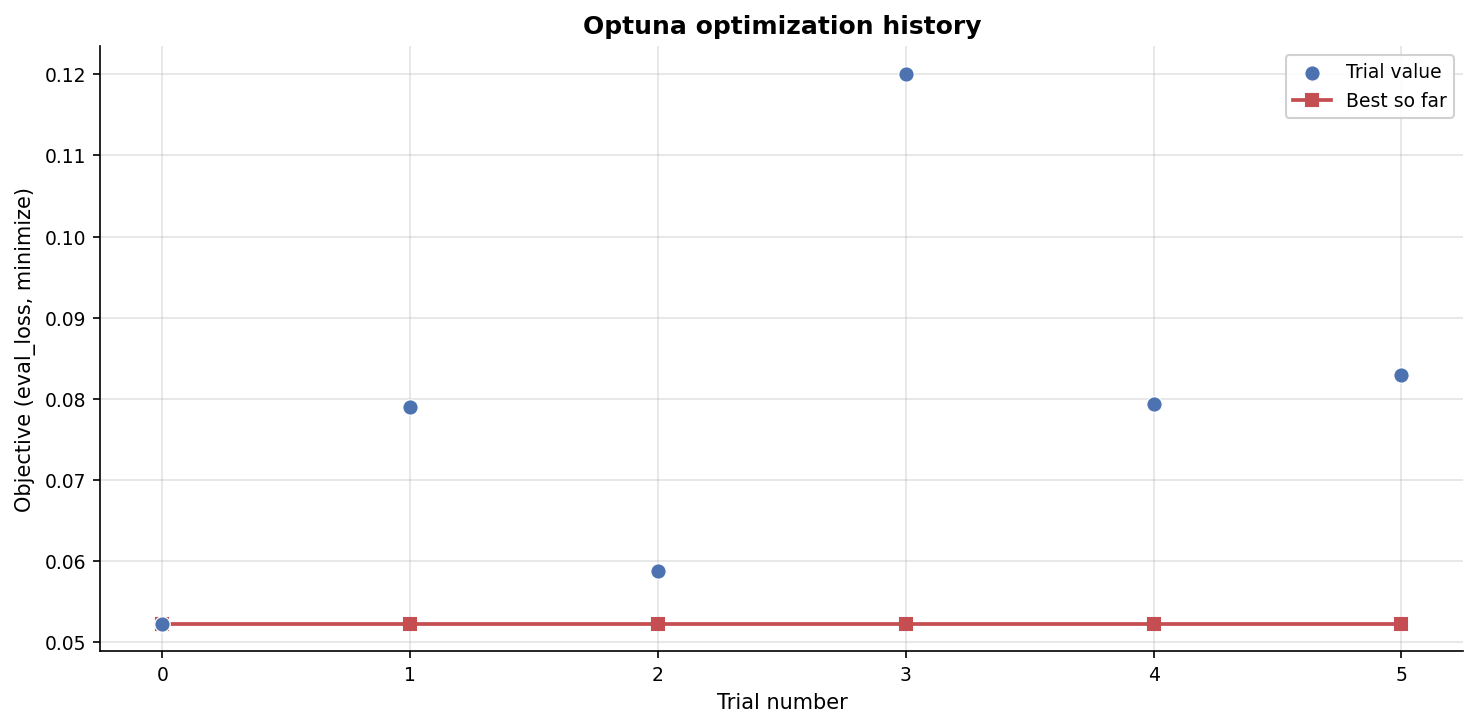
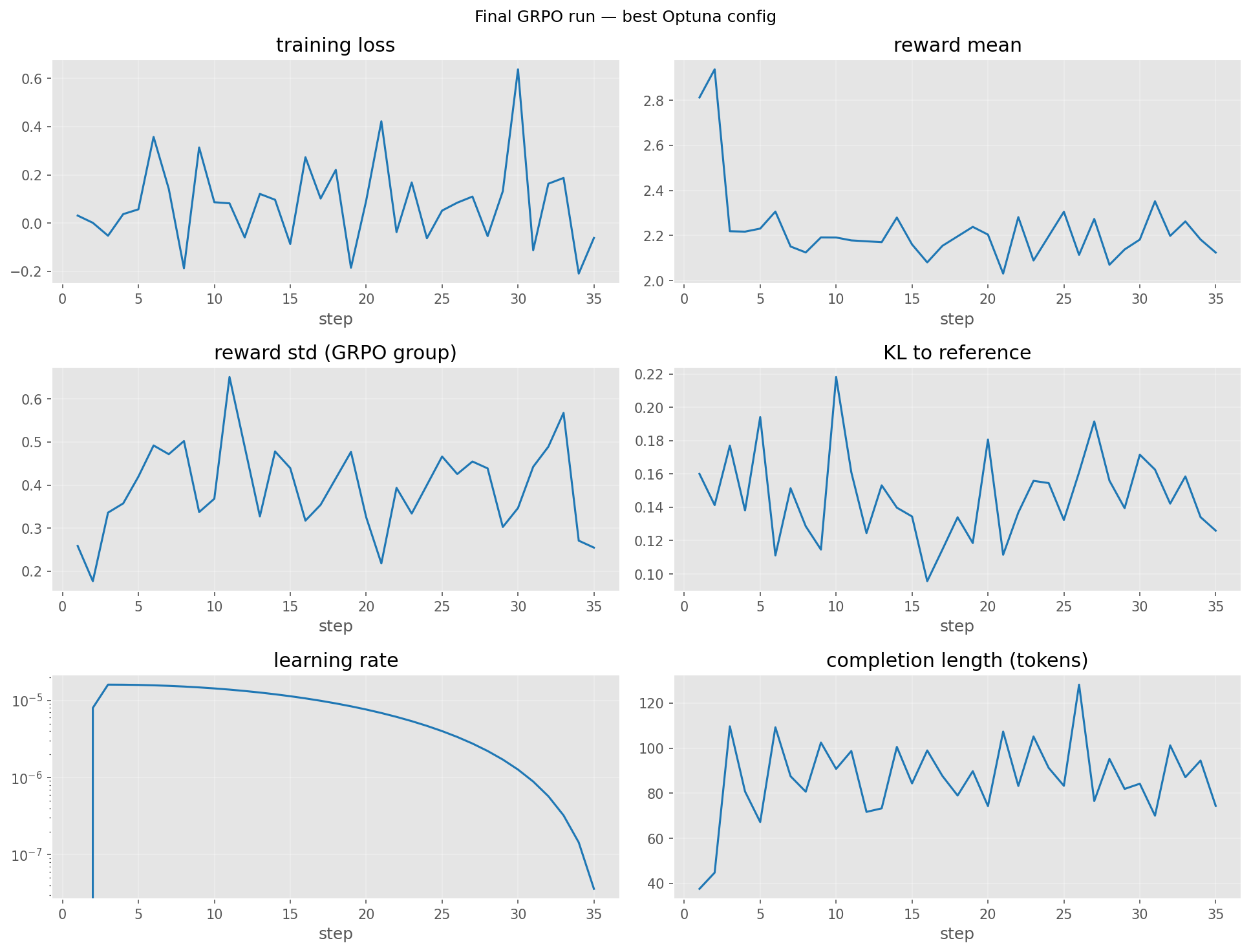
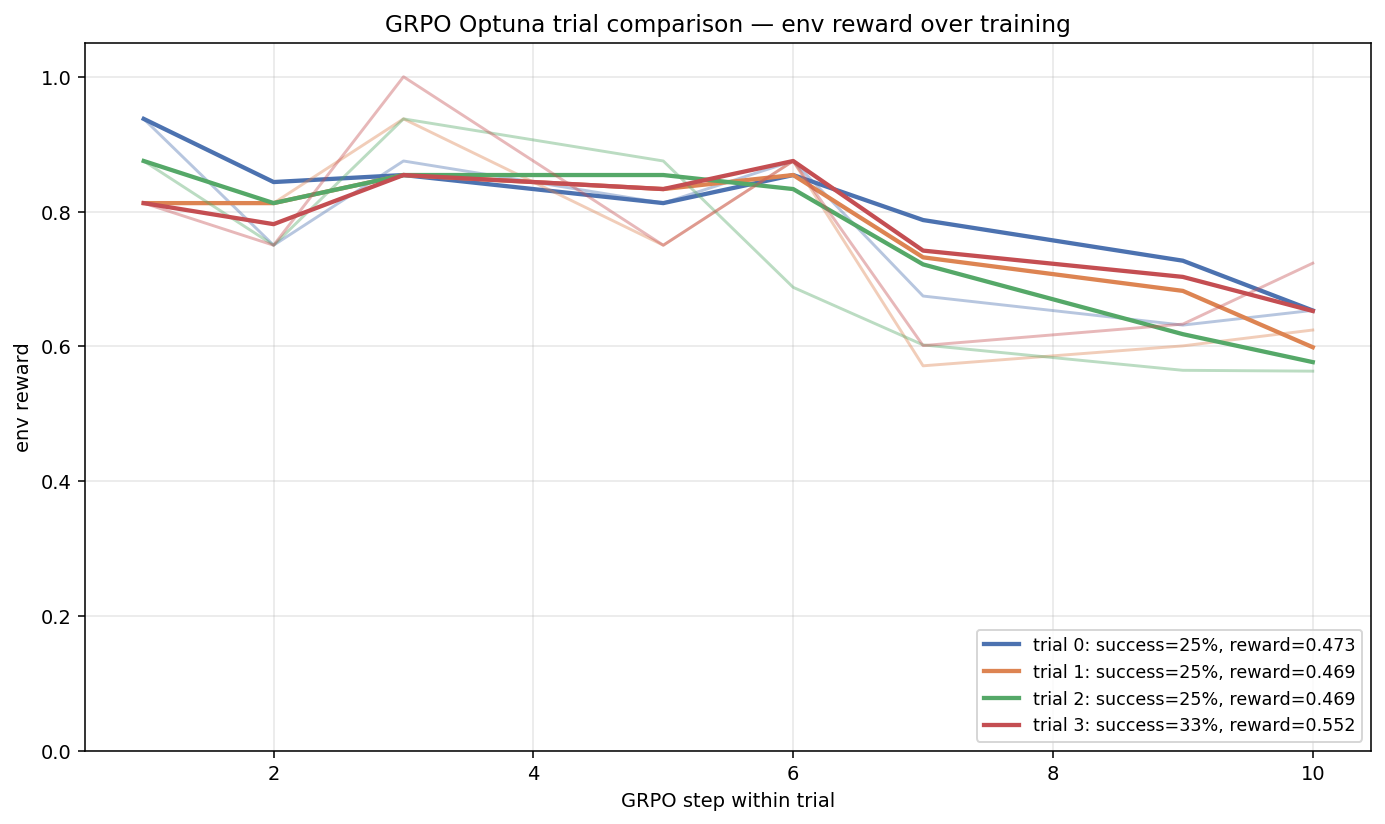
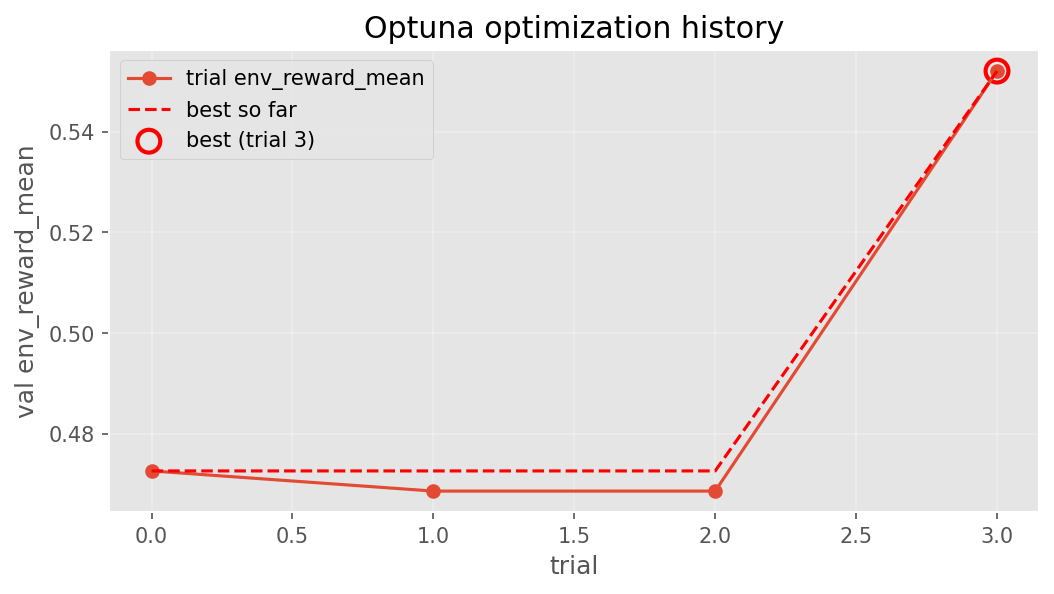
SFT Training Curves & Optuna
Best SFT trial (out of 6): lora_r=16, lora_alpha=16, dropout=0.0058, lr=4.03e-4,
warmup=0.1.
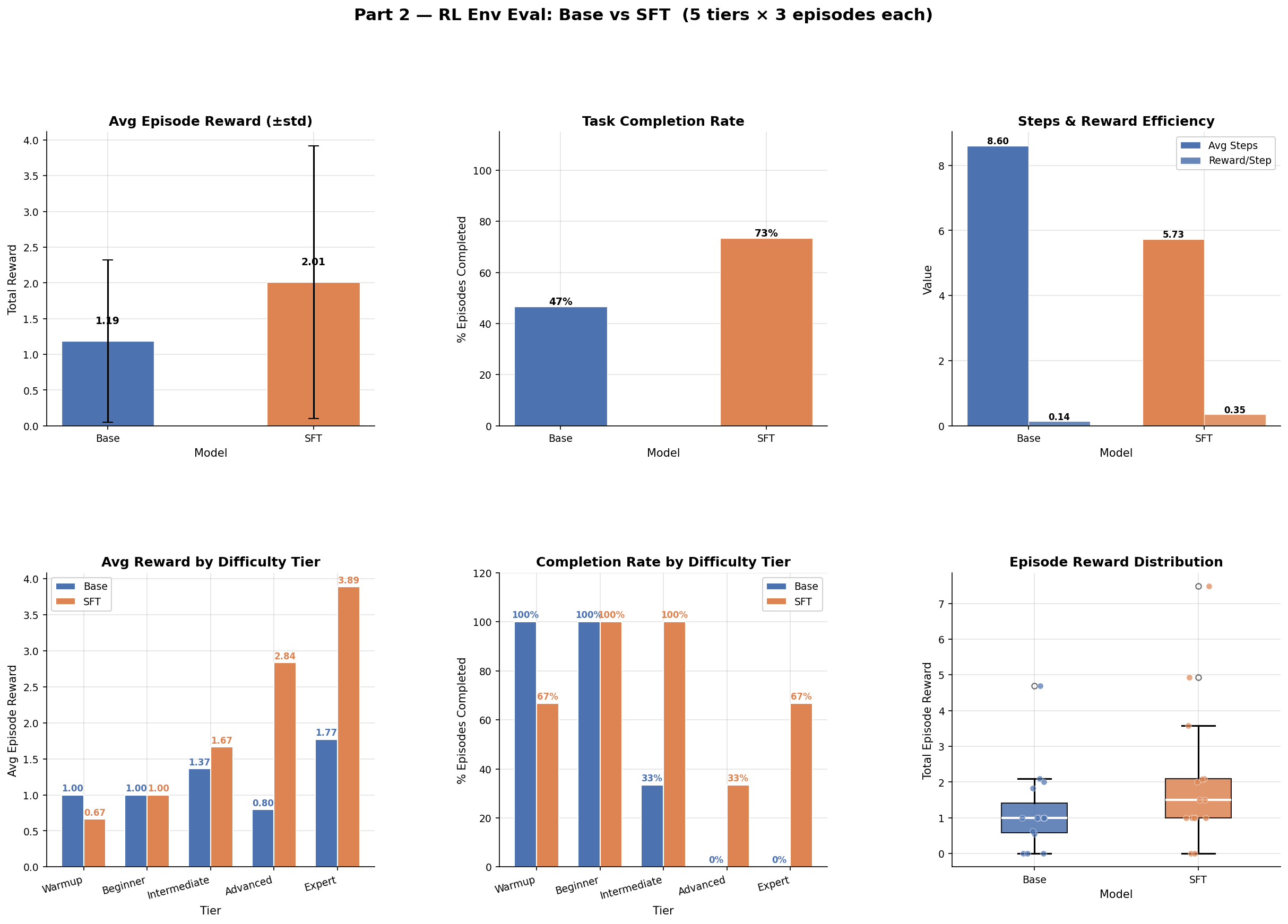
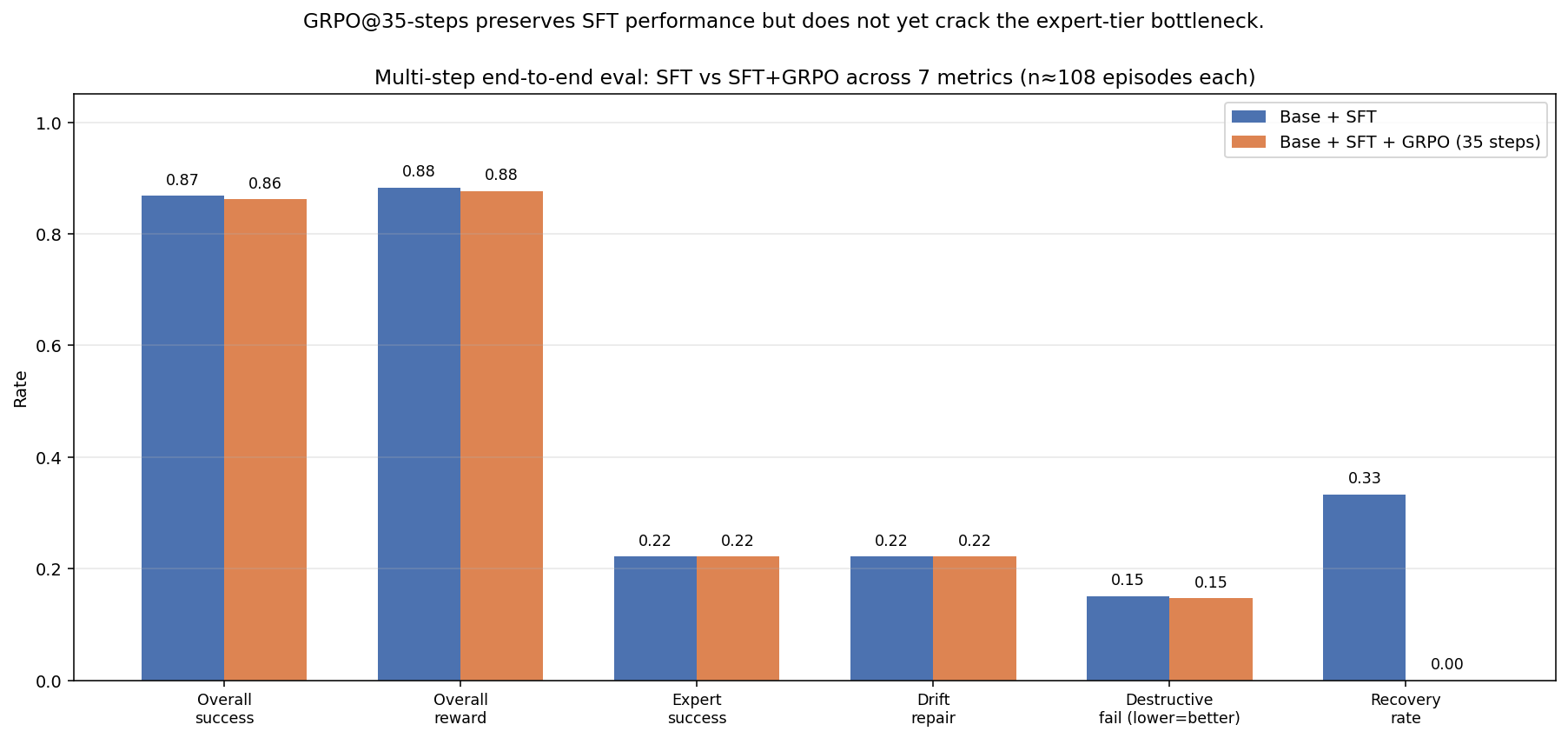
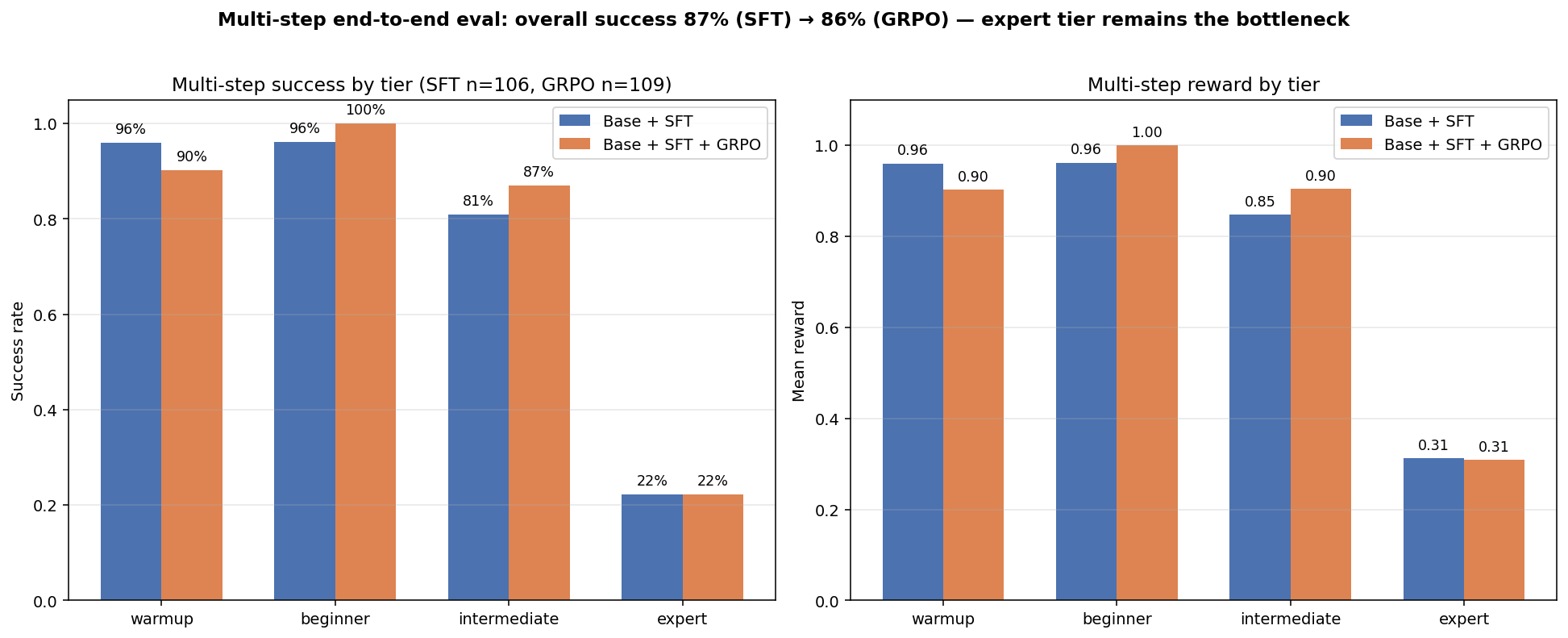
GRPO — Live Multi-step Env Eval
After 35 GRPO steps on top of the SFT adapter (best Optuna config: lr=1.6e-5, β=0.0021,
T=0.99), re-evaluated end-to-end on 100+ episodes.
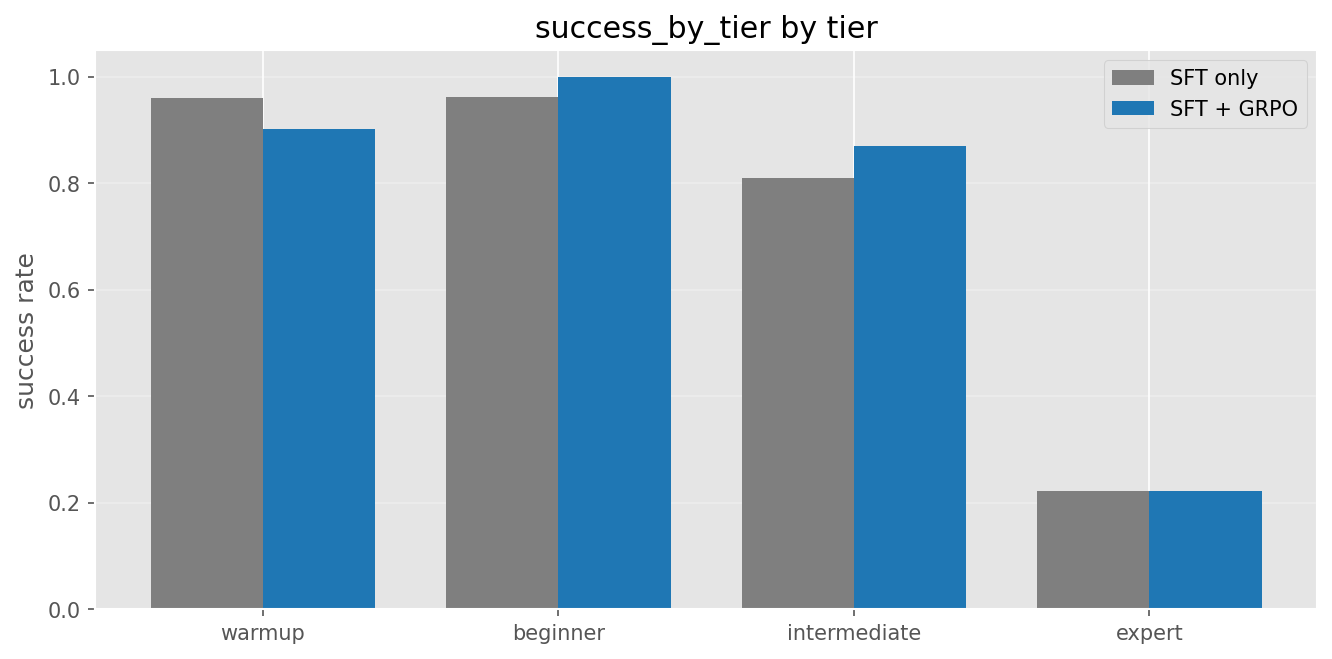
| Metric | Base + SFT | + GRPO | Δ |
|---|---|---|---|
| Overall success | 86.8% | 86.2% | −0.5 pp |
| Beginner | 96.2% | 100.0% | +3.8 pp |
| Intermediate | 81.0% | 87.0% | +6.0 pp |
| Expert | 22.2% | 22.2% | flat |
| Drift repair | 22.2% | 22.2% | flat |
| Destructive-action fail | 15.1% | 14.7% | −0.4 pp |
Honest reading: the 35-step GRPO run preserves the SFT gains and modestly improves the middle tiers, but does not crack the expert-tier bottleneck. Longer runs and more curriculum exposure to expert tasks are next.
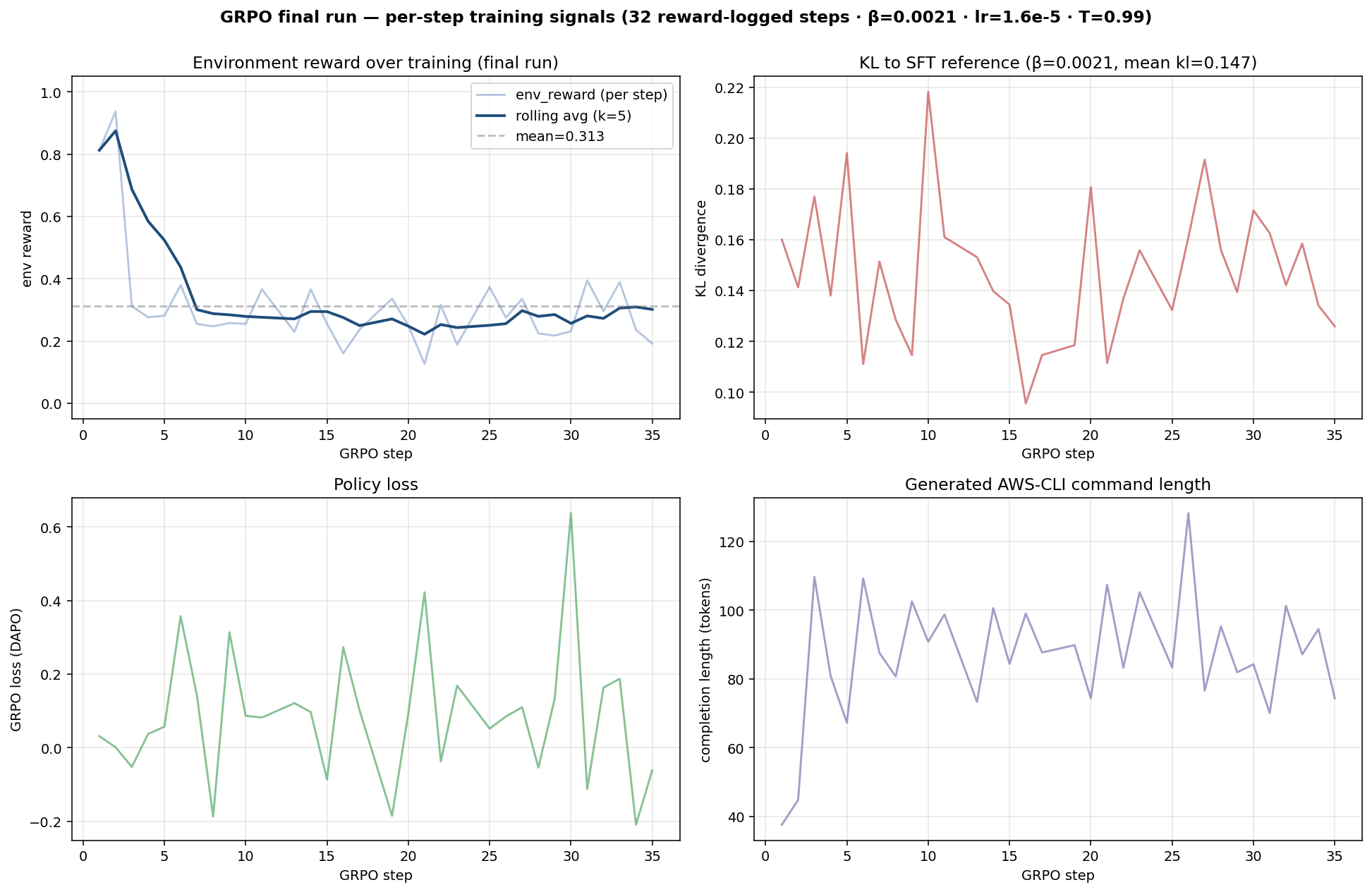
GRPO Training Curves
Per-step training signals from the final 35-step GRPO run, plus the 4-trial Optuna search that picked the final config.
WebSocket
Python Client
Click New Episode to start
The curriculum assigns a task matching your skill level
| # | Command | OK | Reward |
|---|---|---|---|
| No commands executed yet | |||
Start an episode to see live infrastructure state.
Build the Future of AI
This project is made during an Hackathon by Team Vector, (Bangar Raju and Uday Kiran Padhy). Star it, fork it, break it, fix it — every episode makes AI agents better at cloud operations.